










Seien wir ehrlich: Die technologischen Fortschritte der letzten Jahre haben Fachleuten in vielen Branchen geholfen, ihre Workflows zu automatisieren und zu verschlanken, aber der Elektronikeinkauf und Category Manager sind zurückgeblieben. Warum?
Einerseits haben Sie die dialogorientierte Bedienbarkeit generischer KI-Tools (wie ChatGPT), die intuitiv sind, aber oft die technische Präzision vermissen lassen, die für komplexe Sourcing-Prozesse erforderlich ist; andererseits gibt es Enterprise-Software, leistungsstark und präzise, aber sperrig, starr und unter einem Berg von Excel-Tabellen vergraben – oft nicht einmal cloudbasiert.
Die schlechte Nachricht: Dieses „Entweder-oder“-Szenario hat die ohnehin komplexe Realität des Elektronikeinkaufs nur noch komplexer gemacht.
Die gute Nachricht: Heute schließt sich diese Lücke offiziell.
Bei Luminovo freuen wir uns sehr, ElectronicsGPT der Welt vorzustellen – den ersten KI-Agenten, der gezielt für Fachleute im Elektronikeinkauf entwickelt wurde. Auf Echtzeitdaten aus der Supply Chain basierend und auf die einzigartigen Workflows von Sourcing-Managern zugeschnitten, verbindet ElectronicsGPT das Gehirn eines Branchenexperten mit der Oberfläche eines modernen digitalen Assistenten.
Warum der Einkauf einen speziell entwickelten Agenten braucht – nicht nur einen Chatbot
Die Elektronikbranche bewegt sich schnell, und traditionelle Software kommt nicht immer hinterher. Preisschwankungen, geopolitische Risiken und plötzliche Nichtverfügbarkeit treten sehr kurzfristig auf, und oft müssen Sie die Informationen proaktiv recherchieren – was das Ganze eher zu einer Belastung als zu irgendetwas anderem macht.
ElectronicsGPT verändert die Spielregeln und bietet drei zentrale Vorteile:
1. Echtzeitdaten mit Bodenhaftung (ohne Datenschutzrisiko)
Die meisten KI-Tools sind nur so gut wie ihr letztes Trainingsdatum. ElectronicsGPT ist anders: Es basiert auf proprietären Echtzeitdaten aus dem Web und der Luminovo-Plattform.
Entscheidend ist, dass diese Daten kontinuierlich aktualisiert werden und sich auf öffentlich verfügbare Lieferanteninformationen konzentrieren. Falls Sie sich das gefragt haben: Wir geben die Kundendaten von Luminovo nicht weiter. So erhalten Sie präziseste Markteinblicke zu Millionen von Bauteilen, aktuellen Lieferzeiten und Preisen, ohne proprietäre Informationen preiszugeben.
2. Immer aktive Hintergrundaufgaben
Stellen Sie sich einen Junior Buyer vor, der nie schläft. ElectronicsGPT führt Agentenfunktionalität in Form von Aufgaben ein, die autonom laufen können, auch wenn Sie nicht an Ihrem Schreibtisch sind.
Sie können diese Aufgaben so konfigurieren, dass sie in regelmäßigen Intervallen ausgeführt werden, um:
Preisniveaus überwachen: Erhalten Sie sofort eine Warnung, sobald ein kritisches Bauteil Ihren Zielpreis erreicht.
Verfügbarkeit nachverfolgen: Erhalten Sie eine Benachrichtigung, wenn die Lagerbestände eines risikobehafteten Bauteils zu sinken beginnen.
Risiken bewerten: Planen Sie wöchentliche Berichte zu geopolitischen Verschiebungen oder lieferantenspezifischen Risiken.
Und vieles mehr: Sie können Aufgaben für jede Anwendung erstellen, die Ihnen einfällt.
Statt manueller täglicher Checks kehren Sie einfach zu Ihrem ElectronicsGPT zurück und finden die mühsame Arbeit bereits erledigt vor!
3. Sofortige Datenblatt-Extraktion und -Analyse
Wir wissen, dass ein erheblicher Teil der Zeit eines Einkaufsmanagers darauf entfällt, technische Dokumente aufzuspüren und zu entschlüsseln. ElectronicsGPT kann komplexe Datenblätter in nur wenigen Sekunden für Sie abrufen, lesen und erklären.
Ob Sie spezifische technische Anforderungen extrahieren oder eine Drop-in-Alternative für ein veraltetes Bauteil finden müssen – fragen Sie einfach. Unser KI-Agent versteht die Nuancen der Elektronikentwicklung und versetzt Sie in die Lage, schneller denn je von „Suche“ zu „Entscheidung“ zu wechseln.
Das Beste aus beiden Welten: Enterprise-Power, Consumer-Einfachheit
ElectronicsGPT ist nicht einfach nur ein weiteres Tool für Ihren Stack; es ist eine neue Arbeitsweise. Indem wir die Lücke zwischen hochgradigen Enterprise-Daten und einer dialogorientierten Oberfläche schließen, geben wir Einkaufsteams Zeit zurück.
Kein Durchforsten dutzender Tabs mehr. Keine manuelle Dateneingabe mehr. Nur noch eine einfache, intuitive Konversation mit einem Agenten, der Ihre Branche genauso gut versteht wie Sie. Sehen Sie sich das Video an und legen Sie los!
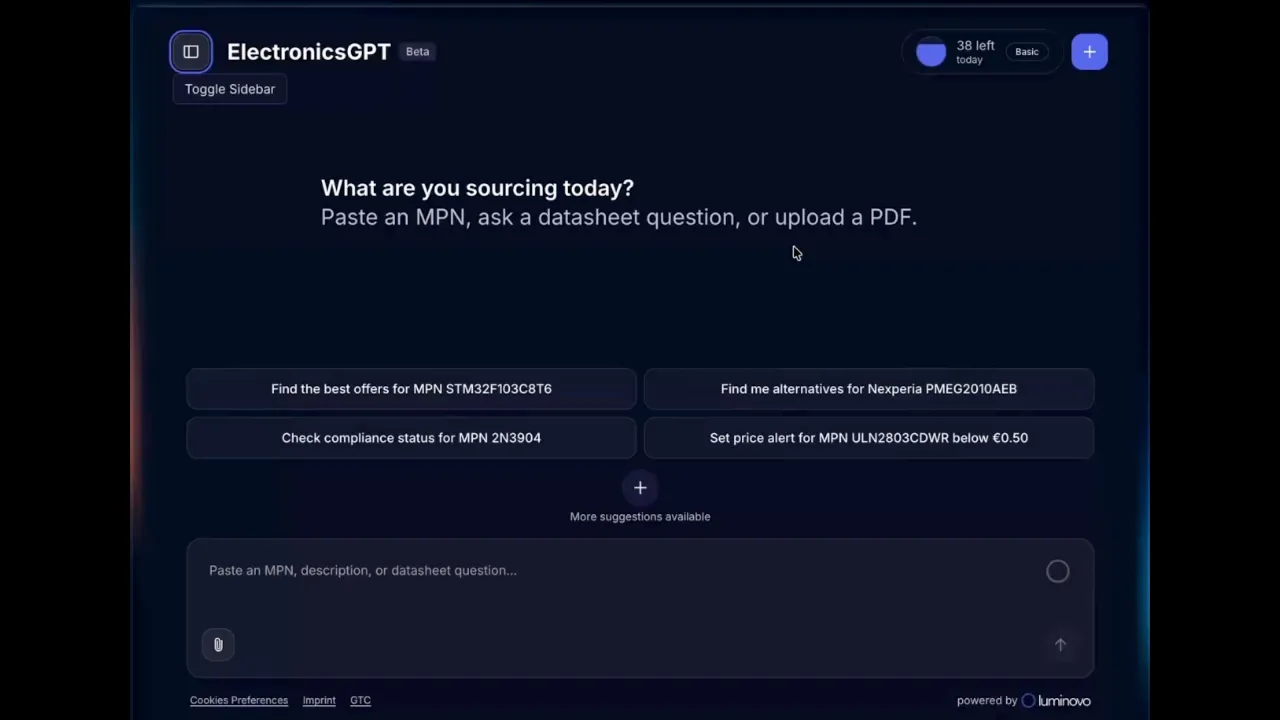
Starten Sie noch heute kostenlos
ElectronicsGPT ist ab Januar 2026 kostenlos verfügbar.
Sind Sie bereit, veraltete Stolpersteine im Einkauf hinter sich zu lassen und eine neue Ära der Workflow-Automatisierung zu nutzen?
Testen Sie ElectronicsGPT jetzt unter www.electronicsgpt.luminovo.com














