








Zurück zum Blog
Datenschutz im maschinellen Lernen


Gründer und Geschäftsführer bei Luminovo
Published:
Arguably, 2018 was the most relevant year for data privacy since the Snowden leaks in 2013.
GDPR came into effect in May, presenting the first extensive rewrite of privacy law in Europe. It was the consequence of a breathtaking series of scandals: Cambridge Analytica had collected and exploited Facebook user data; vulnerabilities in Google+ had exposed data from half a million users; 25 million unique passport numbers had been stolen in a Marriott International data breach.
The value of collecting data has skyrocketed ever since, and debatable partnerships, like GlaxoSmithKline getting access to genetic data from 23andMe, continue to emerge as a consequence thereof.
Privacy breaches have of course provoked counterstrategies, both legal, like GDPR, and technological. To prevent personal information from being vulnerable in the first place, identities are often masked in the process of data anonymization. Stripping confidential information of its identifiers seems straightforward in principle – fields containing names or social security numbers can easily be removed from a database.
How is it then still possible to reconstruct an individual’s identity from anonymized data, and why is the issue of data privacy particularly relevant in the context of AI?
First, we will briefly look at the dimensions of datasets, which are relevant to understand the issue of de- and re-identification. We will then proceed to discuss why the issue of data privacy is uniquely challenging in Machine Learning, and present the newest developments in the field of privacy-preserving AI. Machine Learning and its subcategories (i.e., Deep Learning), represent powerful statistical techniques. However, it is exactly their ability to derive actionable insights from large multidimensional datasets that presents an unforeseen challenge to the field of data security.
The structure of a dataset
Within a database, the various data points associated with an individual can be distinguished from a privacy standpoint, by what class of information they contain. A dataset is a table with n rows and m columns. Each row represents information relating to a specific member of a population; the values in the m columns are the values of attributes associated with the members of the population (e.g. in the case of medical records that might be name – age – gender – state – religion – disease). The first represents Personally Identifiable Information (PII), which uniquely identifies a person, e.g., their full name or social security number. The second type of information contained is termed Quasi-Identifiers (QI), which are categories like age or gender that may be attributable to more than one individual. Therefore, this information on its own is not sufficient for identification. However, if combined with other QIs, query results, and external information, it is sometimes possible to re-identify an individual – more on that later. The third subtype is sensitive columns, which contain protected attributes that should not be traceable to the individual’s identity, e.g. HIV diagnosis.
The issue of de- & re-identification
A famous case of de-anonymization that first brought attention to weaknesses in data protection involved the then-governor of Massachusetts, William Weld. In 1997, the Massachusetts Group Insurance Commission (GIC) released de-identified hospital data to researchers, which was stripped of PIIs. The governor William Weld himself had assured the public that GIC had sufficiently protected patient privacy by deleting identifiers. At the time, Latanya Sweeney was an MIT graduate student in computer science, working on computational disclosure control. By combining QI’s contained in voting records with the anonymized insurance records, Sweeney identified the Governor’s health records, including diagnoses and prescriptions.
It has been argued that this case was exceptional in that the identified individual was a known figure that had experienced a highly publicized hospitalization. However, the concept has been repeatedly proven: cross-referencing publicly available databases and narrowing down matches to ultimately attribute sensitive information to an individual can endanger the publication of data sets, even if stripped of identifiers. In 2008, Narayanan and Shmatikov successfully re-identified a dataset published by Netflix containing anonymized ratings of 500.000 users, by linking it to the Internet Movie Database (IMDb). Ten years later, a group at MIT again de-anonymized the Netflix Prize dataset, this time using publicly available Amazon review data. In 2006, AOL released search queries to the public, and specific users were identified. Most famously, user no. 4417749, with a search history including queries like “60 single men”, or “dog that urinates on everything”, was identified as 62-year old Thelma Arnold from Lilburn, Georgia. Several papers have shown examples of successful re-identification attacks on health data; in conclusion, it can be said that Weld’s case does not stand as an isolated incident.
Why the issue of data privacy is amplified in Machine Learning
Machine Learning is a subset within the field of AI, that allows a computer to internalize concepts found in data to form predictions for new situations. To reach reliable levels of accuracy, models require large datasets to ‘learn’ from. In order to shield individual privacy in the context of big data, different anonymization techniques have conventionally been used. The three most relevant are k-anonymity, l-diversity, and t-closeness. In k-anonymity, specific columns of QI’s (e.g., name, religion) are removed or altered (e.g., replacing a specific age with an age span), so that within the dataset there will now always be at least 2 rows with the exact same attributes (this would then be “2-anonymity”). L-diversity and t-closeness are extensions of this concept, which are described in more detail here. These modifications are applied before data is shared; this is called Privacy-Preserving Data Publishing. However, with the rise of AI, this form of protection may not be sufficient anymore.
Which data security challenges are specific to AI? Many of the privacy challenges cited in the context of big data are also relevant to AI, e.g., being able to re-identify personal information using large datasets, using only minimal amounts of personal information, or lack of transparency of how consumer data is used. The rise of AI is quantitatively different with respect to the enormous amounts of data involved on the one hand, e.g., Baidu using decades of audio data to train their voice recognition algorithm. On the other hand, there is the high dimensionality of data that is considered by models.
Conventional statistical techniques would take into account a limited number of carefully selected variables. Due to novel regularization techniques and decreasing computational cost (also due to cloud services offered by Google or AWS), the possible feature space has drastically expanded, so that ML models can now consider thousands of variables to make a single prediction. One notable example is Google’s use of neural networks to reduce their cooling bill by 40%. The mining of unstructured data through Deep Learning techniques, and the ability to incorporate all this data within a model has lead to unforeseen abundance of information. With algorithms that can make inferences from such large and complex datasets, three new conceptual issues arise.
For one, with the added dimensionality in ML training sets, implicitly there is a higher likelihood of sensitive information being included. Further, these powerful new models are more likely to be able to discern that sensitive information. Finally, the challenge of de-identifying and securing these vast amounts of data that may be incorporated into an ML model is much more difficult, and incorporating protection into complex multilayered architectures presents a major challenge.
What might be some practical examples of threats to data privacy that are specific to AI systems?
ML-specific data privacy challenges
Traditionally, removing the column containing sensitive information in a dataset meant that this specific information could not be re-inferred from the dataset itself, but only from meticulous combining and querying of external information. AI, however, can recreate identities even with the identity-indicator removed. From a set of submitted CVs, gender might be removed to protect against gender discrimination during the evaluation process. Although the resumes have been de-identified in that sense, an ML tool might be able to pick up subtle nuances in language use and from this infer the candidate’s gender. Here, removing the column is not enough to strip out sensitive information securely, and techniques like k-closeness are not applicable without making heavily intrusive changes.
Information contained within the structure of NN models themselves poses a further threat. A trained model incorporates essential information about its training set, and it has been argued that it is relatively straightforward to extract sensitive information from Machine Learning classifiers. In transfer learning, AI models are initially trained on a data set which is stored locally. In order to avoid this data to be shared, the model parameters are transferred to another user, who can then use the model’s discriminatory abilities for prediction, without accessing the personal information from which it learned. However, specific characteristics of the dataset can in some cases be inferred from the shared parameters of the model, and then traced back to uncover sensitive information. The information memorized from data sets by NNs can be extracted through statistical inference in multiple ways, as described by Harvard computer scientist Cynthia Dwork.
Building on the concept of transfer learning, there are more elaborate forms of collaborative learning, which are also based on the idea of collecting and exchanging parameters, thus removing the need for data sharing. A new threat is presented by Generative Adversarial Networks (GANs), which, rather than classifying images into categories, are trained to generate similar-looking samples to the training set, without actually having access to the original samples. The GAN interacts with the discriminative deep neural network in order to learn the data’s distribution; in a way, this presents an extension of the previously described attack.
In conclusion, AI amplifies existing privacy issues and creates entirely new concerns that must be tackled. Knowing this, while also bearing in mind the remarkable value of ML systems, new approaches within the implementation of privacy-preserving machine learning seem more in need than ever.
Current trends in privacy-preserving machine learning
First approaches towards increased data privacy mostly centered around the use of transfer learning, i.e., the use of a pre-trained model for a new problem. By removing access to the original data, there should be reduced privacy concerns. However, as the above examples show, conventional transfer learning lacks a privacy guarantee when it comes to sensitive data. Decentralized, collaborative approaches such as Federated machine learning (FL) are widely used, e.g., by Google, who propose to use decentralized data residing on end devices such as mobile phones, to train their machine learning models. However, GANs pose a fundamental threat to these systems. In a 2017 paper, researchers from Stevens Institute of Technology argue that any distributed, federated, or decentralized Deep Learning approach is susceptible to attacks that reveal information about participant information from the training set. The attack they developed exploits the real-time nature of model learning, which allows the adversary to train a GAN that generates prototypical samples of the private training set. Thus, the notion of deception is also introduced in collaborative learning, which has been considered as privacy-preserving.
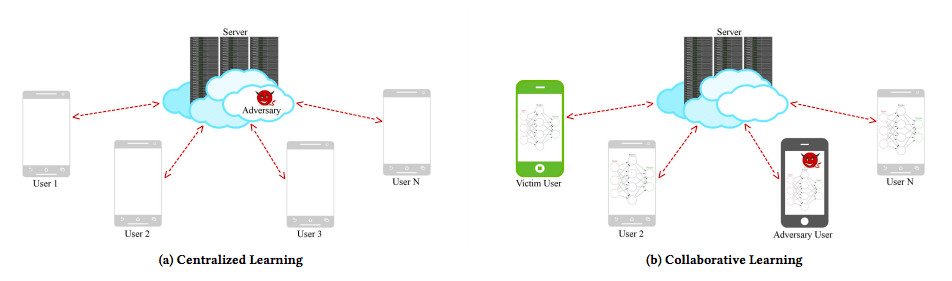
Distributed deep learning can be (a) centralized, in which case the server can compromise the privacy of the data, or (b) distributed, in which case a malicious user employing a GAN could deceive a victim device into releasing private information (Image source)
Enter … Differential Privacy
One of the most promising approaches within privacy-preserving machine learning is differential privacy (DP). The concept is not new within the debate around privacy protection. First formulated by Dwork in 2006, DP represents a stringent privacy notion guaranteeing that no individual patient’s data has a significant influence on the information released about the dataset. This does not mean that nothing about an individual can be learned from the released information - publishing data showing a strong correlation between smoking and lung cancer reveals sensitive information about an individual known to smoke. Rather, the ultimate privacy goal is to ensure that anything that can be learned about an individual from the released information, can be learned without that individual’s data being included. In general terms, an algorithm is differentially private if an observer examining the output is not able to determine whether a specific individual’s information was used in the computation. For a server containing sensitive information, a query function will retrieve true answers from the database. To protect individual privacy, random noise is generated according to a carefully chosen distribution, which will lead to perturbation of the true answer. The true answer plus noise is returned to the user. The degree of perturbation can be accounted for so that overall accuracy does not significantly decrease, while for individual data there always remains “plausible deniability” due to randomness of the noise.
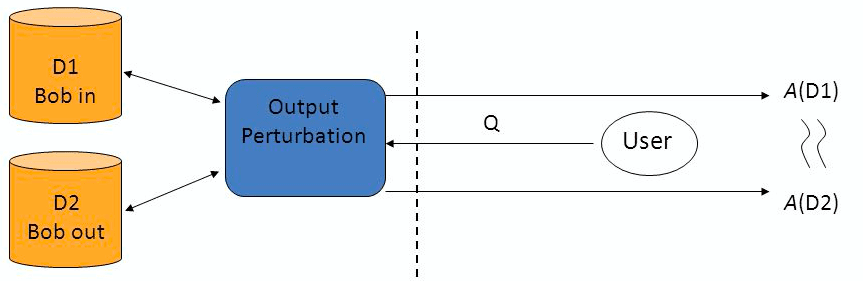
Differential privacy requires the outcome to be formally indistinguishable when run with and without any particular record (in this case Bob’s) in the dataset (Source: mathcs.emory.edu)
A surprising property of differential privacy is that it is mostly compatible with, or even beneficial to, meaningful data analysis despite its protective strength. Within empirical science, there is the threat of overfitting data to ultimately reach conclusions that are specific to the dataset, and lose accuracy when predictions are generalized to the larger population. Differential privacy also offers protection from such overfitting, its benefits thus go even beyond data security. These strengths of DP are more pronounced for some data types than others; generally, DP works well for low-sensitivity queries with Gaussian distributions. Limitations arise when working with smaller datasets with uneven distributions, e.g. dataset of incomes containing extreme outliers, where more noise must be added, or during adaptive querying. If you can ask a series of differentially private queries, statistical inference attacks might gradually derive the form of underlying noise distribution. Also, in a series of k queries that are differentially privatised, we must inject k times the noise; when k is large, this eventually destroys the utility of the output. In conclusion, differential privacy is a highly promising line of research, that can provide for powerful protection, but cannot yet be adapted to all situations, and is currently hard to incorporate within complex systems. One attempt to outline a methodology for practical use was formulated by researchers from Harvard Medical School in 2018. The paper presents a method to train neural networks on clinical data in a distributed fashion under differential privacy.
Practical implications
In the field of data privacy, there is a discrepancy in described threats, explored by academia with the aim of eliminating the mere possibility of any vulnerability, and feasible attack scenarios. While theoretical problems are important to consider, one must be realistic about the genuine risk they present. All the re-identification and data reconstruction efforts described above stem from research groups with the goal of improving current methods; and it is safe to say that these efforts have consistently been time- and labor-intensive with the outcome of randomly identifying one elderly woman out of thousands without any clear motive. These efforts, involving multiple highly skilled computer scientists for hundreds of hours, would seem to hardly pay off in the case of malicious intent. Nevertheless, we should aim for all our models to be theoretically sound, especially in the context of data privacy. Pragmatically, one must be careful not only with data sharing, but also sharing of architectures, and consider building up internal systems aided by experts, that mainly rely on own data. This may be hard to achieve at first, in particular for small to middle-scale businesses, which is where a hybrid human-AI approach becomes practical. The idea here is that initially a pre-trained default architecture for the task on hand, e.g. object recognition, is deployed to classify standard cases, while relying on the human expert in edge cases. Through feedback, such a continuously improving model enables early practical use of AI that is also sustainable long-term. From examining the theoretical state of the field of privacy-protecting AI as a whole, we can identify three main concepts: the suitability of transfer learning for data where privacy is secondary, awareness of the vulnerabilities that collaborative models still have, and the significance of differential privacy for future applications.





















