










The development of artificial intelligence and neural networks has greatly impacted the field of Computer Science on the one hand, but it has also drawn significant attention to the field of Neuroscience. The concept of artificial neural networks is inspired by the biology of neurons, in that artificial neurons were designed to rudimentarily mimic how neurons take in and transform information.
As a Neuroscience student, I was initially attracted to neural networks from the perspective of understanding our own cognition better via computational models. However, the fundamental qualitative differences between human and artificial intelligence make it very challenging for us to understand a model’s decision making process in human terms.
AI that is currently in use operates as a “black box” — we can test levels of accuracy on a test set, and then deploy our model on new data with a certain confidence in its outputs, but if challenged, we would struggle to actually explain a model’s decision in individual instances. As a response, the field of explainable AI (XAI) has emerged in research, which aims to develop techniques where the process leading to a model’s output can be understood by humans. This is a challenging task with many hurdles to overcome, which leads to the question of whether interpretability is really necessary from a practical perspective. This question becomes more pressing with the rising popularity of sophisticated machine learning systems, which are not anymore limited to tech titans like Google or Facebook. Small to mid-sized businesses are automating certain procedures within their systems, which will progress into larger-scale automation of decisions that carry substantially more weight, to autonomous control. Technology trends in businesses usually give a good preview of upcoming changes in institutions and governments, where adoption will increasingly follow. With this as an outlook, the discussion of conceptual issues like explainability becomes increasingly urgent.
We will proceed by first looking at three examples of academic approaches that aim to tackle interpretability from different angles. Then we’ll look at the topic conceptually, and discuss whether interpretability is actually necessary in practice . (Spoiler alert: it depends)

Academic work around interpretability
Transparent/explainable AI refers to techniques in AI where the process leading to an output can be understood by humans. It stands in contrast to the “black box” implementations, where one cannot explain why the model arrives at a specific decision. Simply put:
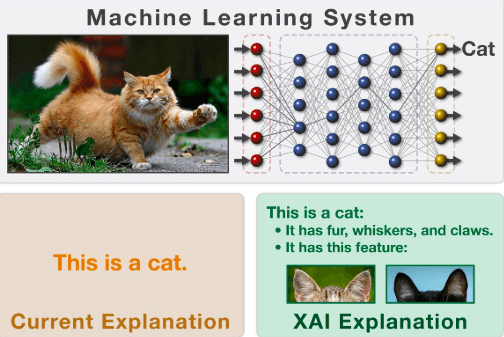
The idea of building models that can be understood in human terms is almost as old as artificial intelligence itself. Mycin, a research prototype that could explain which of its hand-coded rules contributed to a diagnosis in a specific case, dates back to the 1970s. This AI-based expert system was engineered at Stanford University to identify bacteria causing certain infections and recommend antibiotics in a dosage adjusted to the individual’s weight. Mycin operated on a knowledge base of around 600 rules, and the power of this early prototype was fairly limited in comparison to the high predictive power modern deep learning systems exhibit in diagnostic contexts. So what approaches have been pursued since then?
Make neural networks biological again
A classic example of biologically inspired AI is the convolutional neural network (CNN). The features of CNNs are modeled off the basic organization of our visual system. In 1962, Torsten Wiesel and David Hubel made the discovery that our primary visual cortex is made up of two types of neurons. Simple (S-) cells can be thought of as edge-detectors at a specific retinal location. If the edge appears at a different location in your field of view, they will not respond. Complex (C-) cells have more spatial invariance, meaning they will respond to edges of their preferred orientation within a large receptive field. Complex cells achieve this by pooling inputs from multiple simple cells with the same orientation. This was emulated in the precursor of the CNN, the Neocognitron, which is also made up of “S-cells” and “C-cells” that recognize simple images via unsupervised learning.
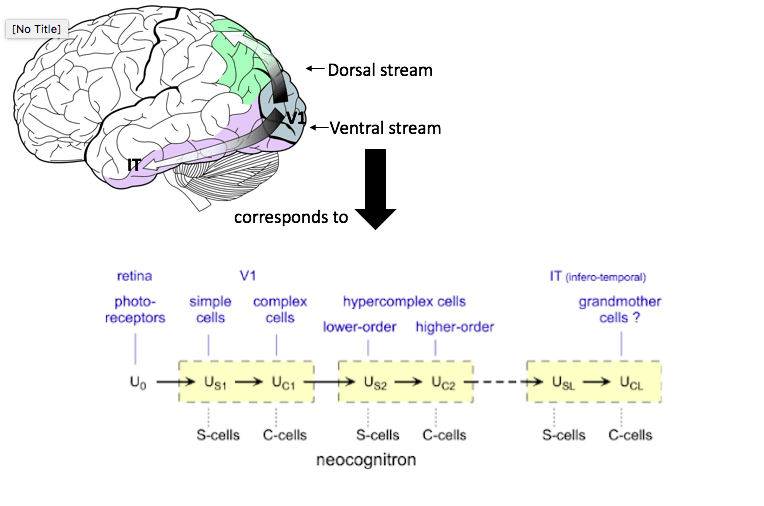
However, the more advanced our deep learning models get, the further away we move from initial biological parallels. Consider how our ventral visual pathway made up of the Lateral Geniculate Nucleus (6 neuronal layers) and the ventral stream (3 neuronal layers V1, V2, V4) enable us to discriminate between different animals with precision comparable or superior to some deep CNNs made up of 100 layers. Neuroscientists have detangled the meaning of individual neuronal layers in visual processing, but trying to understand what each layer of an AI model encodes in human terms is an entirely new challenge. One way of going about this is to comparatively study why the brain can perform so accurately in seemingly fewer computational steps (and from this, try to translate efficiency concepts into our AI models).
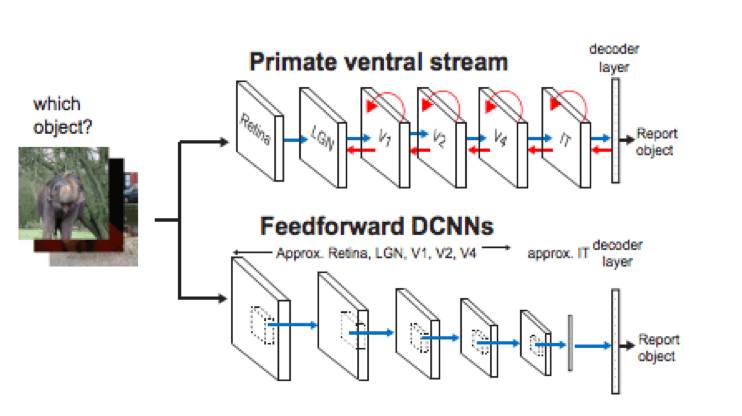
James Di Carlo’s lab at MIT works at the intersection of Neuroscience and Computer Science, researching ways to make neural networks more brain-like. Last year, his group demonstrated the importance of recurrent circuits for our ability to detect objects. They compared deep feedforward CNNs to primates (who, like us, use recurrent feedback circuits) in object recognition tasks. The strong performance of non-recurrent CNNs on object recognition tasks would suggest that such feedback processes are not absolutely necessary for object detection. By comparing CNNs to primate visual processing, DiCarlo identified certain “critical” images which the primate has no issue identifying, while the CNN fails. On this same group of images, deeper CNNs perform better. What does this tell us? a) Recurrent feedback circuits may be part of the reason why our ventral stream needs significantly less neuronal layers than state-of-the-art CNNs, so they are an adaptation for computational efficiency, and b) While for most object recognition tasks, these recurrent operations are not necessary, there may be a small percentage of critical situations for which completely feedforward systems will continue to fail. While fascinating to those interested in Neuroscience, these efforts are aimed at using neural networks to help us understand the brain, rather than using the brain to build more practical or efficient models.
Visualizing neural networks
Another approach encompasses endeavors to create visualization techniques that shed some insight into the inner workings of currently used deep learning systems. I find this particularly fascinating when applied to Generative Adversarial Networks. GANs have been causing a commotion both within research and in popular media, where many have heard of DeepFakes creating realistic images or video sequences of people, or AI-generated artworks being sold for over $400,000. Previously, AI was used to analyze, internalize, and predict, but with the rise of GANs, AI can create. This technology is very powerful, however, we lack an understanding of how a GAN represents our visual world internally, and what exactly determines certain results. Antonia Torralba’s group at MIT has been working to answer these questions. GANs seem to learn facts about objects, and relations between features. To cite an example from Torralba, a GAN will learn that a door can appear on a building, but not on a tree. We know little of how a GAN represents such a structure, and how relationships between objects might be represented. To start making sense of a GAN’s “decision-making process” in human terms, Torralba proposes the following method as a general framework:
First, identify groups of interpretable units that are related to object concepts (e.g. identify GAN units that match trees). Secondly, identify the set of units that causes a type of object (e.g. trees) to disappear. Thirdly, try inserting those object concepts in new images and observe how this intervention interacts with other objects in the image. Let’s look at this using GAN-generated images of churches. We are trying to identify which part of the model generates the object class of trees:
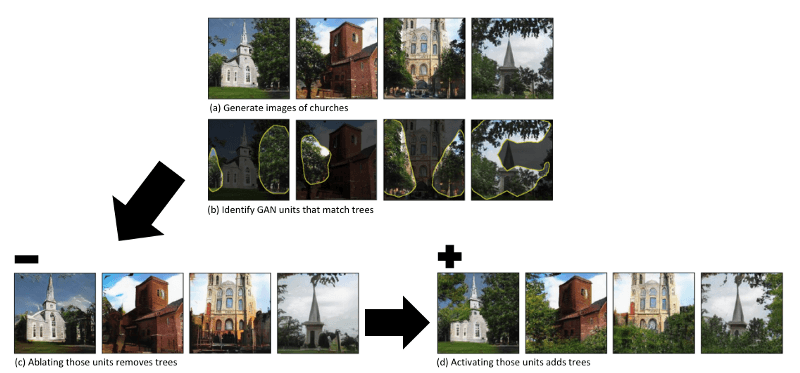
To recap, by identifying units that are necessary for an object class to be generated, we can attribute meaning to parts of our GAN model. Practically, this is useful if we want to improve our GAN in a controlled way (i.e. not just through trial and error or prolonged training). In the following example, we have imperfect GAN-generated images of bedrooms with artifacts perturbing the image. By identifying and ablating the units causing the artifact, we see improved results in the output.

Quantifying Feature Importance
Within the field of model visualization, most efforts center around the visualization of specific image features that individual CNN layers learn to detect. This laborious task becomes even more frightening if one would face the chore of re-building such an interpretability system for every new model. One way of approaching this problem is to pursue the development of unified approaches (i.e. generic interpretability tools that can be applied to different ML models). One such unified framework for interpreting model predictions was created by Lundberg and Lee at the University of Washington in 2017. Their model, SHAP¹, is based on Shapley values, a technique used in game theory to determine how much each player in a collaborative game has contributed to its success. In our case, each SHAP value measures how significantly each feature in our model contributes towards the predicted output of our model. This moves away from concrete explanations of a layer’s “role” (e.g. encoding edges in a particular spatial location) to a more abstract concept of interpretability, where the decision is not understood per se, but the weight of individual components contributing to the output can be detangled. SHAP currently provides the best measure for feature importance, however at huge computational cost, which grows exponentially with the number of input features. For the vast majority of problems, this renders the prospect of complete implementation impractical.
Both researchers that proposed this model developed an ML system in the same year called “Prescience” that promises to predict the risk of hypoxemia (abnormally low blood oxygen) in real time, while also presenting an explanation of factors contributing to the assessed risk (e.g. BMI, age, pulse etc). This might be extremely useful during surgery under anesthesia, where many fluctuating variables must be monitored. While the group belonged to the first to combine a highly accurate model of considerable complexity with interpretable explanations, the authors also acknowledged that their proposal is an initial attempt far from practical implementation due to several shortcomings they describe. The challenge of creating accurate and complex AI systems that also provide intuitive explanations of their decision process will remain a challenge for the foreseeable future, with many promising approaches being proposed within research right now.

The tradeoff between predictive power and interpretability is harder to overcome than one might think: Consider that sometimes the very purpose of building complex models is that they can express complex hypotheses that lie above human understanding. When aiming for systems that acquire the ability to learn and draw predictions from a greater number of features than any human could account for, we must face the possibility that it might conceptually not be possible to account for these high-dimensional predictions in human terms. The “Prescience” model described above visualizes around 15 variables that influenced the model’s decision, but what if the disease prediction model has a million features, and the evidence for a diagnostic decision is spread out among these features? With an interpretability framework that explains a few prominent features, the model itself either has to be limited to only those features, or our visualization would not faithfully describe the model’s behavior, therefore negating its claim to “transparency”.
Practical evaluation
To what extent are these endeavors of practical concern? When answering the question of whether interpretability efforts are worth it, most commentaries tend to take a clear stance on yes or no. Advocates for explainable machine learning will argue that we must always understand how our tools work before we use them. Cooperation, in this case between algorithms and humans, depends on trust, and trust arguably requires a basis, e.g., understanding. If humans are to accept algorithmic prescriptions, they need to trust, and therefore understand them. This argument on its own, I believe, is questionable. Andrew Ng famously said that AI is the new electricity, in the sense that electricity irreversibly changed every industry 100 years before it was fully understood, and AI will do the same. Even before the science behind electrical phenomena was fully explainable, risks could be comprehended and safe usage implemented. Similarly one could argue that with AI, current focus should lie on communicating how these new technologies can be used to our advantage in a wider sense, and what the limits and (rational) dangers are. However, this answer is equally generalizing, and simply dismissing interpretability as a practical concern would be short-sighted. How AI can be used is hugely context-dependent — for one, we must distinguish between industries, and also within sectors between specific use-cases and the gravity of predictions/their consequences.
When speaking about healthcare, one would intuitively assume that interpretability should be prioritized throughout. The first exemption to this is the use of AI to support operational initiatives. Healthcare institutions generate and capture enormous amounts of structured and unstructured data, e.g., in the form of patient records, staffing patterns, duration of hospital stays, and so on. Without too much concern about interpretability, we can deploy highly accurate models with the objective of optimizing patient care and supervision or facilitating the usage of electronic health records. Very different criteria apply to the development of clinical decision systems. We know that for the detection of some cancers, deep learning models can detect critical patterns with higher accuracy than experienced doctors.
However, in many cases there is a lot at stake in these decisions, and while a doctor can explain his decision by naming the decisive factors that shaped his diagnosis, a deep learning model cannot be queried in the same way — for one, because the reason for its higher accuracy is precisely the ability to take into account more factors and complex interactions than can be understood in human terms. Thinking further ahead, this would also pose unprecedented legal issues centered around responsibility — debates of this kind have already been started around autonomous driving. The requirement of explainability might well remain a major obstacle of automated disease detection. A field where the need for explainable AI is less clear lies in medical imaging. As described in this article, one promising application for deep learning is the acceleration of MRI scans by intelligent reconstruction of undersampled images. This is different from automated diagnosis as the model is trained to sharpen and reconstruct details, not detect structures. The accuracy of the reconstruction algorithm can be tested by engineering low-quality images, which serve as input to the model, and then comparing the output to the original image. However, the concern exists that over time the algorithm could develop biases depending on the distribution of its input, which is hard to detect without insight into the model’s inner workings.
In conclusion…
Explainability is important, but not always essential. We don’t necessarily need to understand an AI model as a rule in order to deploy it, however, it should be the long-term goal so that incorporation of deep neural networks also becomes an option in sensitive decision-making processes. It all comes down to a context-dependent tradeoff. Highest accuracy for large modern datasets is often achieved by complex models that even experts struggle to interpret, creating a tension between accuracy and interpretability. For each field, we must compare the value of accuracy and automation with the need for insight into the decision-making process.
While the endeavor of combining both will remain within the realms of research in the near future, we must consider the issue of trust and transparency within the context of a specific task, and design systems tailored to those requirements that still allow us to benefit of the predictive power of AI.
[1] SHapley Additive exPlanations
We at Luminovo appreciate the nuances of individual business problems, and the varying requirements they entail. With the outlook of increasing usage of AI in sensitive decision-making processes, we have been dedicating internal research to building interpretability frameworks for deep neural networks via advanced visualization. While such models, which are based on state-of-the-art research, shed some insight into the internal workings of AI-based systems, full insight into a model’s decision-making process is still a far way ahead. Therefore, our practical solution combines human expert knowledge, which remains unsurpassed in deciphering critical edge cases that deviate from the norm, with continuously improving artificial intelligence within a hybrid system. By incorporating communication through feedback between the user and the model, we make use of the opposed strengths that characterize human and artificial intelligence. This format combines the need for transparency with practical realisability.















